Overview
When streaming large datasets to your application, processing items one at a time can overwhelm your API and slow down data synchronization. Data chunking solves this problem by breaking large arrays into manageable batches, allowing you to process data more efficiently while respecting rate limits.Understanding Data Chunking
As covered in streaming data to a destination, the Stream Data connector sends data from workflows to your webhook endpoints. By default, it streams one item at a time. While this works fine for small datasets, it becomes problematic when dealing with hundreds or thousands of records. Data chunking automatically groups array items into batches of your specified size. Instead of receiving 10,000 individual webhook calls for 10,000 records, you might receive 200 calls with 50 records each. This approach offers several benefits: Reduced API overhead: Fewer webhook calls mean less connection overhead and reduced latency Better rate limit management: Batch processing helps you stay within your API’s rate limits Improved processing efficiency: Your application can process multiple records in a single operation Simplified error handling: Failures affect entire chunks rather than individual items, making retry logic more straightforwardConfiguring Chunk Size
To enable data chunking in the Stream Data connector, click the Optional Parameters dropdown and specify your desired chunk size: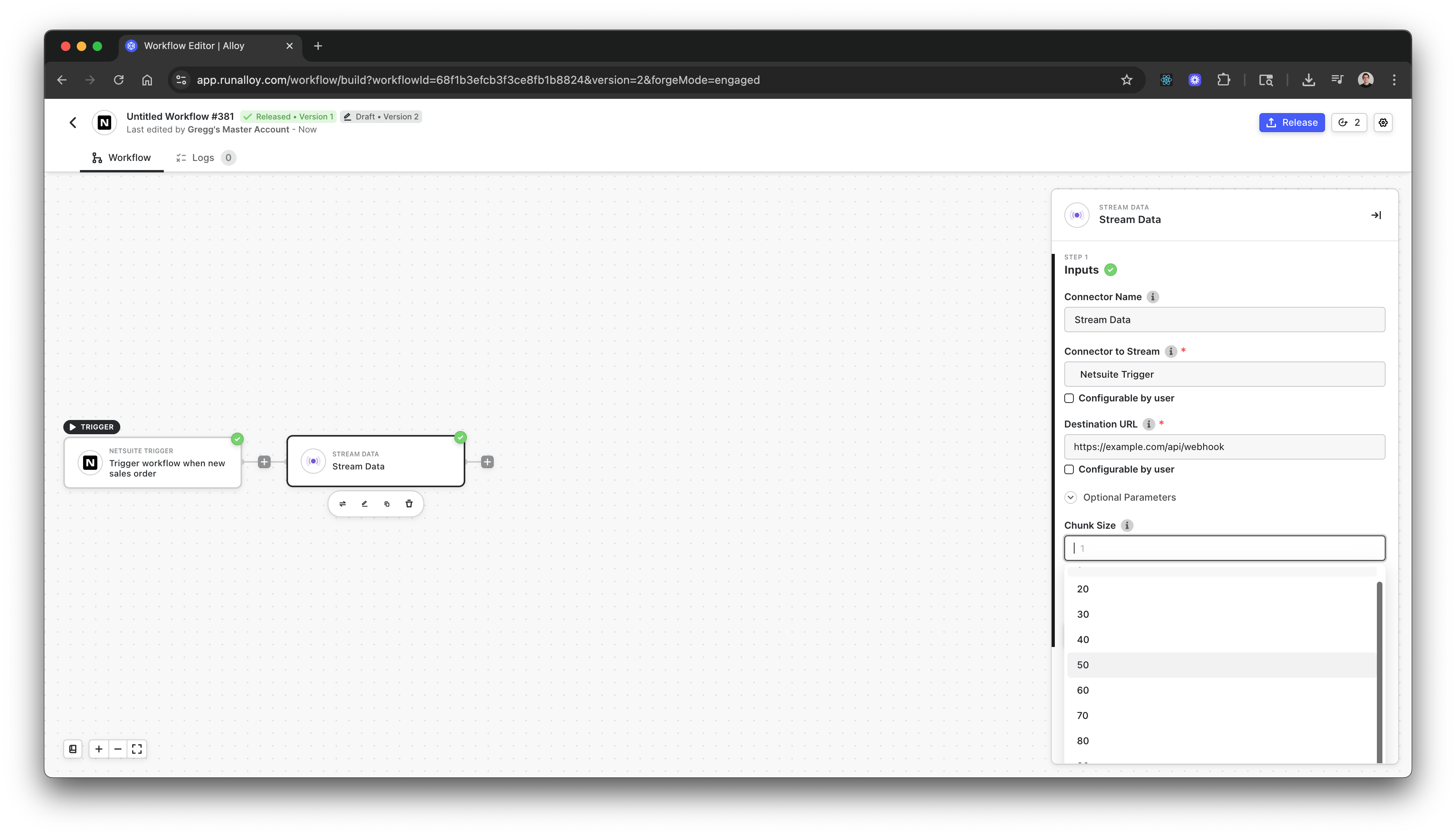
Example: Syncing NetSuite Orders
Consider a workflow that exports a user’s complete NetSuite order catalog. If a store has 10,000 orders, processing them individually would result in 10,000 separate webhook calls to your endpoint. With a chunk size of 50, the workflow instead sends 200 webhook calls, each containing 50 orders. This reduces the total number of API calls by 98% while still delivering all the data your application needs. Here’s what your webhook receives with chunking enabled:JSON